Are you weighing the benefits of cloud storage versus on-premises storage? If so, the right answer might be to use both–and not just in parallel, but in an integrated way. Hybrid cloud is a storage environment that uses a mix of on-premises and public cloud services with data mobility between the two platforms.
IT professionals are now seeing the benefit of hybrid solutions. According to a recent survey of 400 organizations in the U.S. and UK conducted by Actual Tech, 28 percent of firms have already deployed hybrid cloud storage, with a further 40 percent planning to implement within the next year. The analyst firm IDC agrees: In its 2016 Futurescape research report, the company predicted that by 2018, 85 percent of enterprises will operate in a multi-cloud environment.
Hybrid has piqued interest as more organizations look to the public cloud to augment their on-premises data management. There are many drivers for this, but here are five:
- We now have a widely-accepted standard interface.
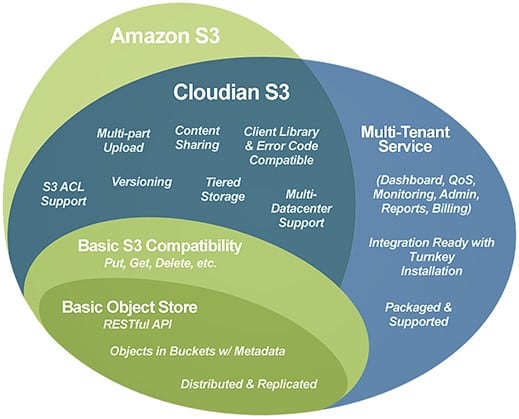
The emergence of a common interface for on-prem and cloud storage changes everything. The world of storage revolves around interface standards. They are the glue that drives down cost and ensures interoperability. For hybrid storage, the defacto standard is the Amazon S3 API, an interface that began in cloud storage and is now available for on-premises object storage as well. This standardization is significant because it gives storage managers new flexibility to deploy common tools and applications on-prem and in the cloud, and easily move data between the two environments to optimize cost, performance, and data durability.
- Unprecendented hybrid scalability delivers operational efficiency.
Managing one large, scalable pool of storage is far more efficient than managing two smaller ones. And hybrid storage is hands-down the most scalable storage model ever devised. It combines on-prem object storage – which is itself scalable to hundreds of PBs – with cloud storage that is limitlessly scalable, for all practical purposes. This single-pool storage model reduces data silos, and simplifies management with a single namespace and a single view — no matter where the data originated or where it resides. Further, hybrid allows you to keep a copy of all metadata on-premises, ensuring rapid search across both cloud and on-premise data.
- Best-of-breed data protection is now available to everyone.
Data protection is fundamental to storage. A hybrid storage model offers businesses of all sizes incredible data protection options, delivering data durability that previously would have been affordable to only the most well-heeled storage users. In a hybrid configuration, you can backup data to object storage on premises, then automatically tier data to the cloud for long-term archive (Amazon Glacier, Google Coldline, Azure Blob). This gives you two optimal results: You have a copy of data on-site for rapid recovery when needed, and a low-cost, long-term archive offsite copy for disaster recovery. Many popular backup solutions including Veritas, Commvault and Rubrik provide Amazon S3 connectors that enable this solution as a simple drop-in.
- Hybrid offers more deployment options to match your business needs.
Your storage needs have their own nuances, and you need the operational flexibility to address them. Hybrid can help with more deployment options than other storage models. For the on-premise component, you can select from options that range from zero-up-front cost software running on the servers you already own, to multi-petabyte turnkey systems. For the cloud component, a range of offerings meet both long-term and short-term storage needs. Across both worlds, a common object storage interface lets you mix-and-match the optimal solution. Whether the objective is rapid data access on-premises or long-term archival storage, these needs can be met with a common set of storage tools and techniques.
- Hybrid helps meet data governance rules.
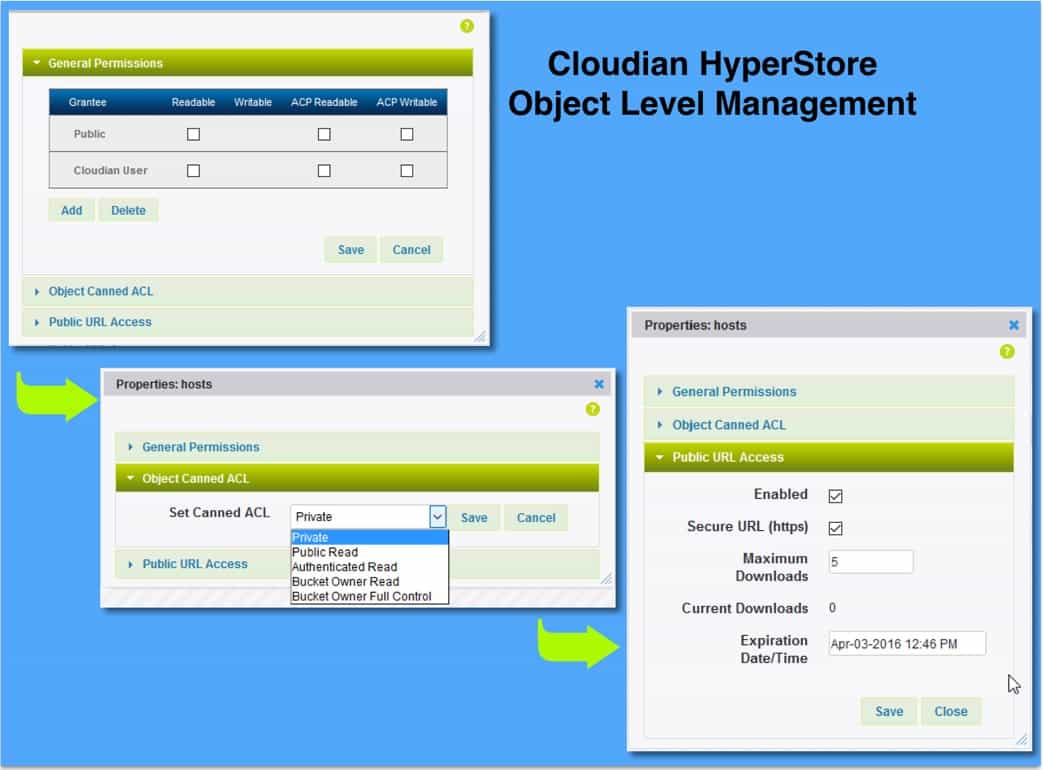
External and internal data governance rules play a big part in data storage planning. In a recent survey, 59% of respondents reported the need to maintain some of their data on premises. On average, that group stated that only about half of their data can go to the cloud. Financial data and customer records in particular are often subject to security, governance and compliance rules, driven by both internal policy and external regulation. With a hybrid cloud model, you can more easily accommodate the changing needs. With hybrid, you can set policies to ensure compliance, tailoring migration and data protection rules to specific data types.
While many are seeing the natural advantages of hybrid, some are still unsure. What other factors play in that I haven’t mentioned? With more and more being digitized and retained into perpetuity, what opportunities is your organization exploring to deal with the data deluge?
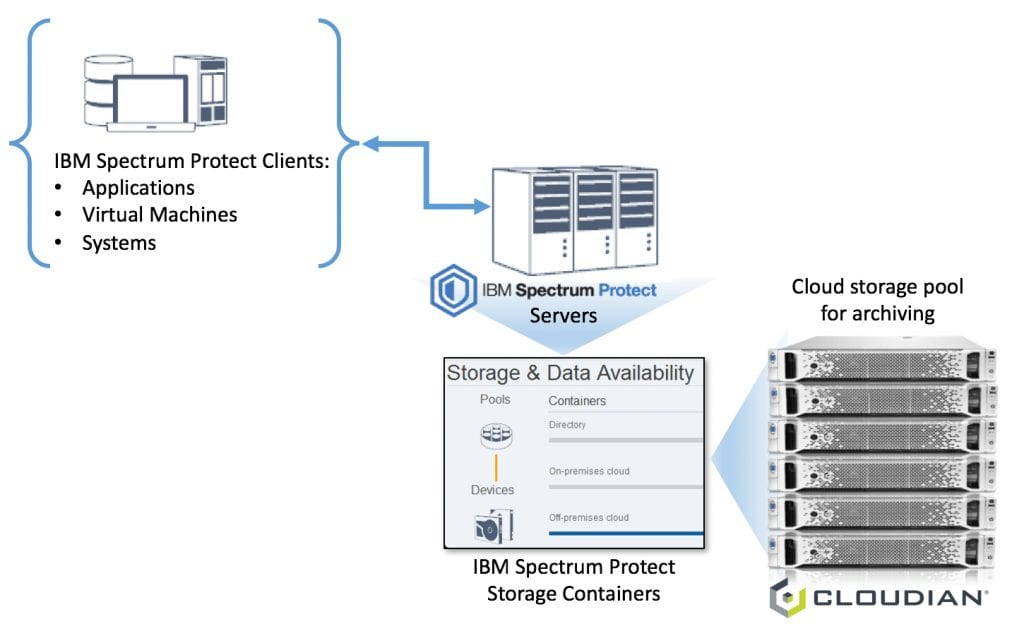

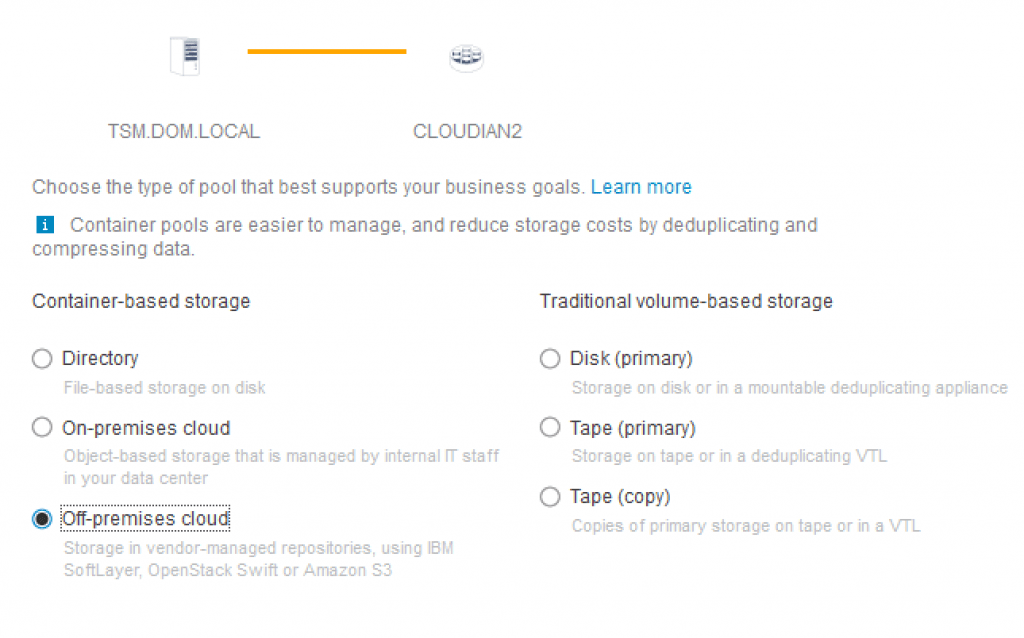
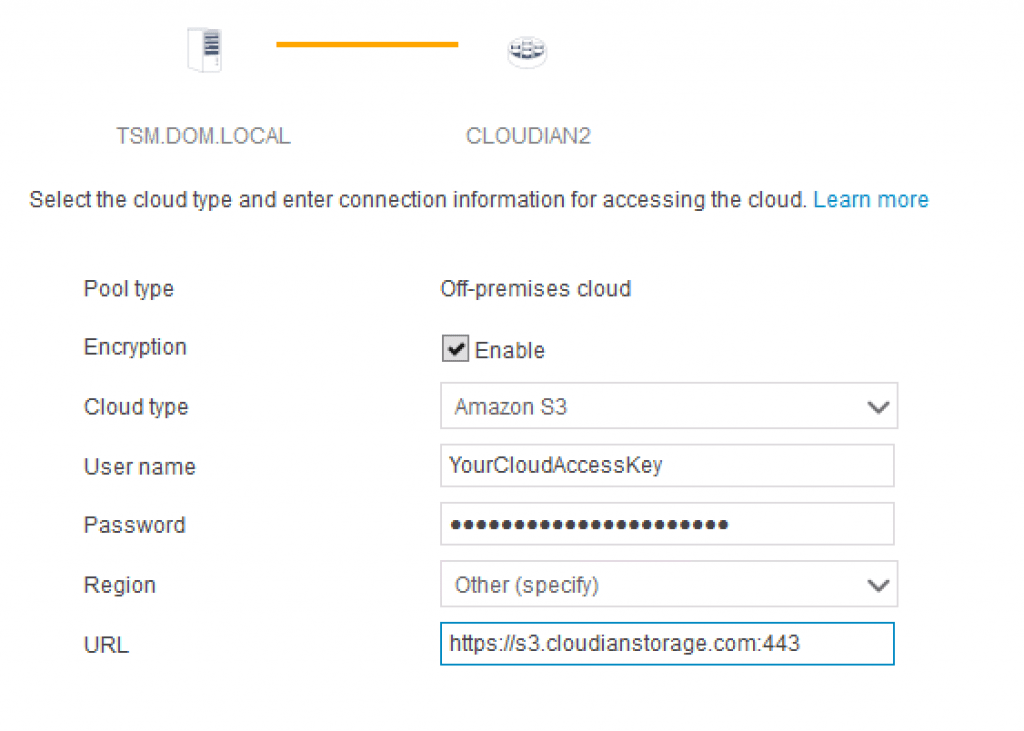
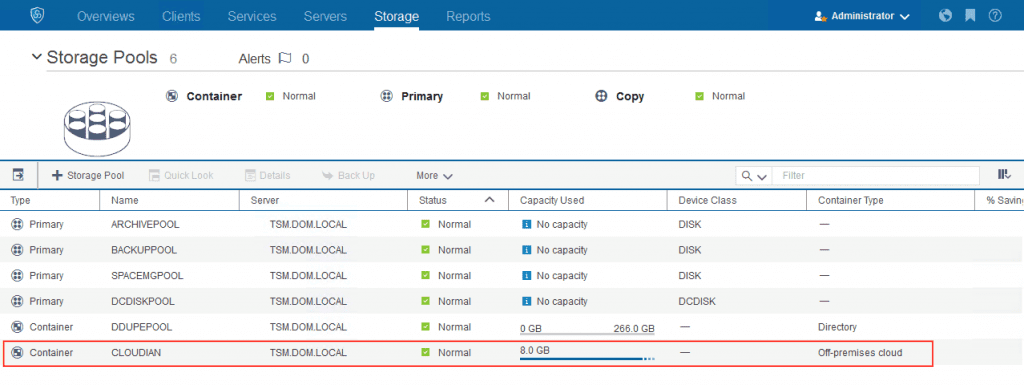
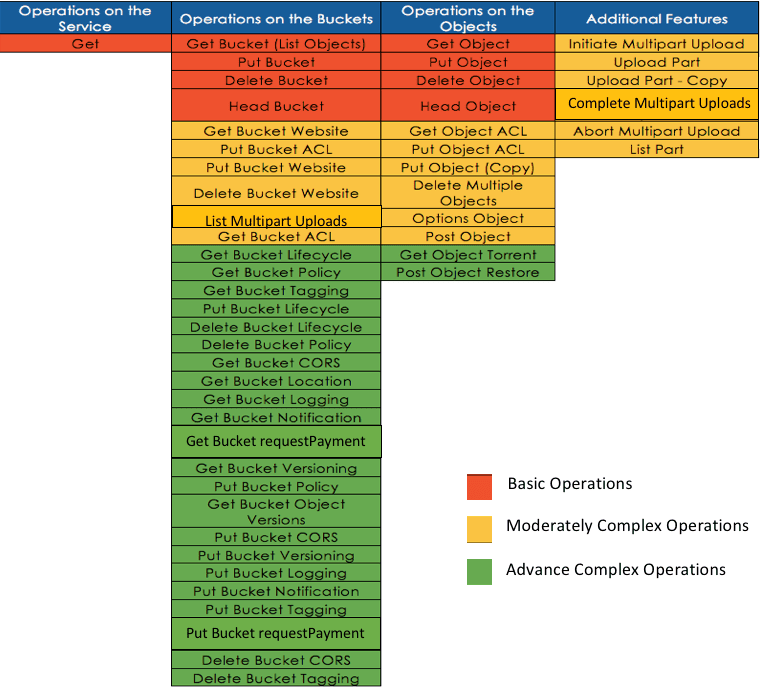




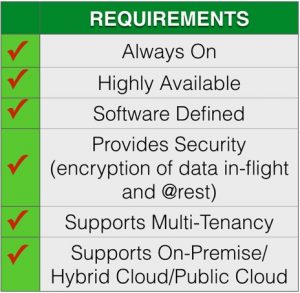 But in order to serve and protect your data for the always on, always available IoT world, what requirements should we take into account before deploying any data protection or storage solution? If you are a data protection geek, you’ll most likely see some of your requirements being listed on the right. If you are a data protection solutions provider, you guys definitely rock! Data protection solutions such as Commvault, NetBackup, Rubrik, Veeam, etc. are likely the solutions you have in-house to protect your corporate data centers and your mobile devices. These are software-defined and they are designed to be highly available for on-premise or in-the-cloud data protection.
But in order to serve and protect your data for the always on, always available IoT world, what requirements should we take into account before deploying any data protection or storage solution? If you are a data protection geek, you’ll most likely see some of your requirements being listed on the right. If you are a data protection solutions provider, you guys definitely rock! Data protection solutions such as Commvault, NetBackup, Rubrik, Veeam, etc. are likely the solutions you have in-house to protect your corporate data centers and your mobile devices. These are software-defined and they are designed to be highly available for on-premise or in-the-cloud data protection.