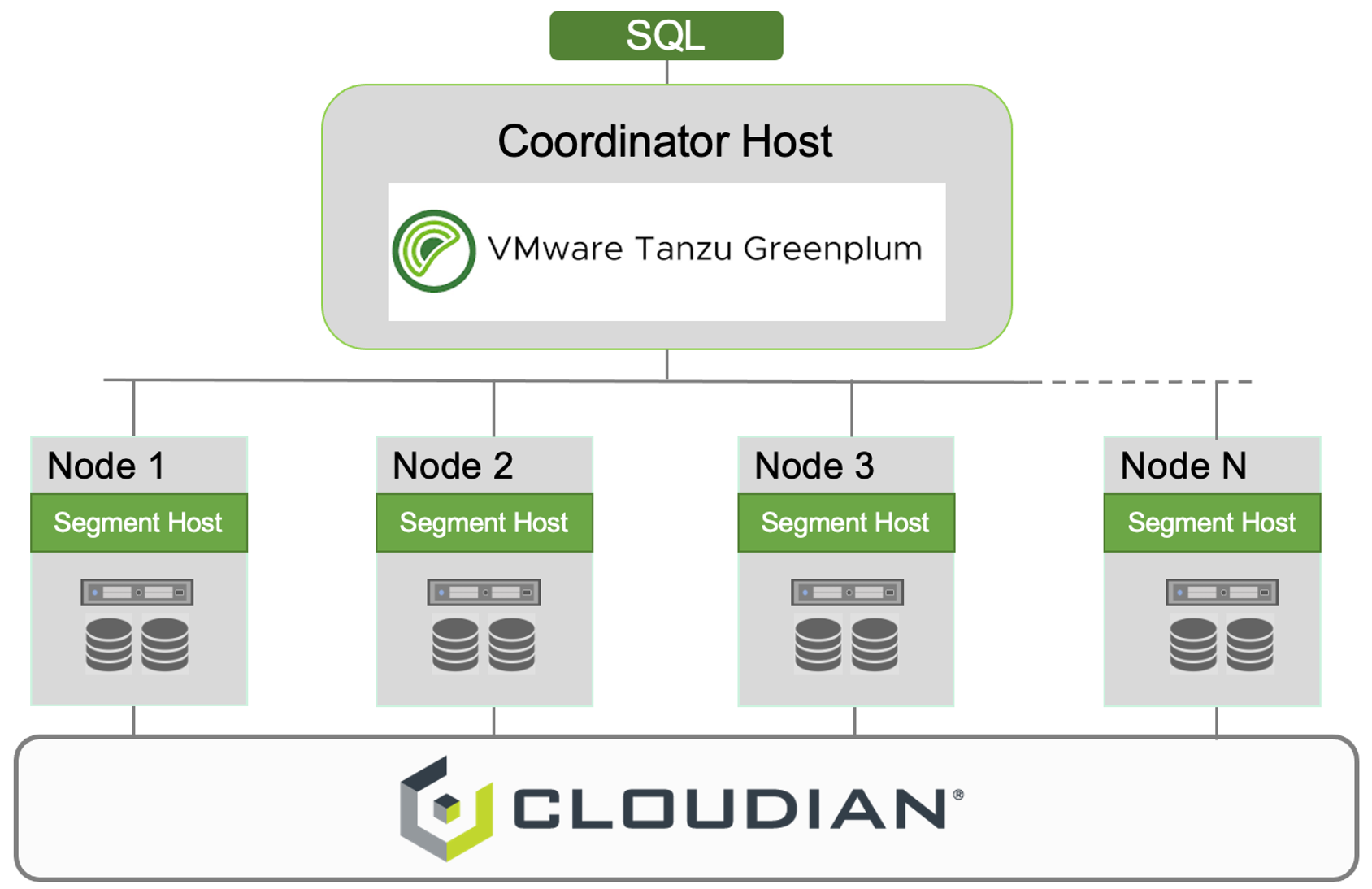
Cloudian is expanding its collaboration with VMware with a new solution combining Cloudian HyperStore with VMware Tanzu Greenplum, a massively parallel data warehouse platform for enterprise analytics, at scale.
Integrating Cloudian enterprise-grade object storage with VMware Tanzu Greenplum enables new efficiencies and savings for Greenplum users while also supporting the creation and deployment of petabyte-scale advanced analytics models for complex enterprise applications. This is especially timely with the amount of data consumed and generated by enterprises accelerating at an unprecedented pace and the need for these applications to capture, store and analyze data rapidly and at scale.
Whether your analytics models use traditional enterprise DB data; log & security data; web, mobile & click steam data; or your models use video and voice data; IOT data or JSON, XML geo and graph data; the need for a modern data analytics platform solution that is affordable, manageable, and scalable has never been greater.
Cloudian HyperStore, with its native S3 API and limitless scalability is simple to deploy and easy to use with VMware Tanzu Greenplum. HyperStore storage supports the needs for data security, multi-clusters, and geo-distributed architectures across multiple use cases:
- Storing database backups
- Staging files for loading and unloading file data
- Enabling federated queries via VMware Tanzu Greenplum Extension Framework (PXF)
Learn more about this new solution, here and see in the Greenplum Partner Marketplace
See how Cloudian and VMware are collaborating: https://cloudian.com/vmware
Learn more about Cloudian® HyperStore®