The enterprise storage industry is going through a massive transformation, and over the last several years I’ve had the good fortune of being on the front lines. As founding CEO of Nexenta, I helped that company disrupt the storage industry by creating and leading the open storage market. These days I’m having a blast as a senior advisor and investor at companies including Cloudian, who is taking off as a leader in what is typically called “object storage”.
In this blog I’d like to share what I’m seeing – across the IT industry – and why change is only accelerating. The sources of this acceleration are much larger than any one technology vendor or, indeed, than the technology itself.
Let’s start at the top – the top of the stack, where developers and their users reside. From there we will dive into the details before summarizing the implications for the storage industry.
Software eats everything
What does “software eats everything” really mean? To me it means that more than ever start-ups are successfully targeting entire industries and transforming them through technology-enabled “full stack” companies. The canonical example is a few guys that thought about selling better software to taxi companies… and instead became Uber.
Look around and you’ll see multiple examples where software has consumed an industry. And today, Silicon Valley’s appetite is larger than it ever has been.
So why now? Why is software eating everything? A few reasons:
- Cloud and AWS – When I started Clarus back in the early 2000s, it cost us at least $7 million to get to what we now would call a minimum viable product. These days, it costs perhaps 10% of that, largely thanks to the shift to the cloud. Maybe more importantly, thanks to SaaS and AWS, many users now see that cloud-hosted software is often safer than on-premises software.
- SaaS and Cloud have enabled a profound trend: DevOps – DevOps first emerged in technology companies that deliver software via the cloud. Companies such as Netflix, Facebook, and GitHub achieve developer productivity that is 50-60x that of older non-DevOps approaches. Highly automated end-to-end deployment and operations pipelines allow innovation to occur massively faster – with countless low risk changes being made and reverted as needed to meet end user needs.
- Pocket sized supercomputers – Let’s not forget that smartphones enable ubiquitous user interactions and also smart-sensing of the world – a trend that IoT only extends.
- Open source and a deep fear of lock-in – Open source now touches every piece of the technology stack. There are a variety of reasons for this including the role that open source plays as a way for developers to build new skills and relationships. Another reason for the rise of open source is a desire to avoid lock-in. Enterprises such as Bank of America and others are saying they simply will *not* be locked in again.
- Machine learning – Last but not least, we are seeing the emergence of software that teaches itself. For technology investors, this builds confidence since it implies a fundamental method of sustaining differentiation. Machine learning is turning out to the be the killer-app for big data. This has massive second-order effects that have yet to be fully considered. For example, how will the world change as weather prediction continues to improve? Or will self-driving cars finally lead to pedestrian-friendly suburban environments in the US?
Ok, so those are at least a few of the trends…let’s get more concrete now. What does software eating everything – and scaring the heck out of corporate America wrestling with a whole new batch of competitors – mean for storage?
Macro trends drive new storage requirements
Let’s hit each trend quickly in turn.
1) Shift to AWS
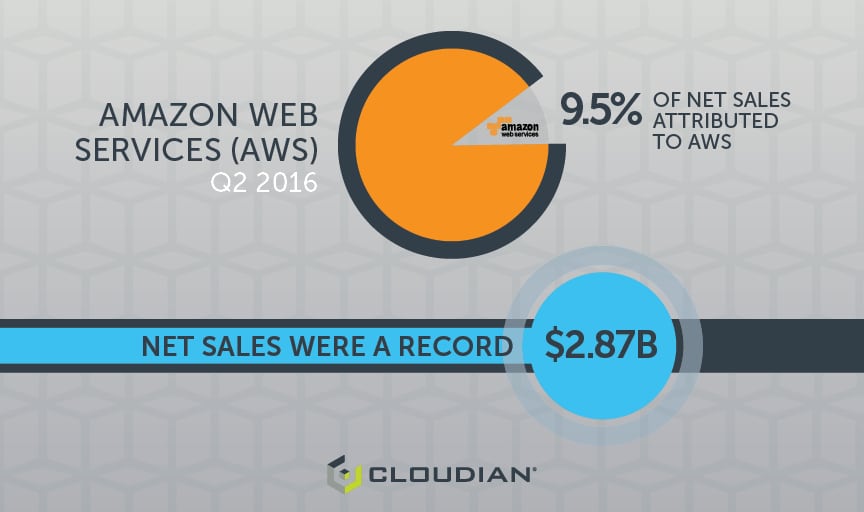
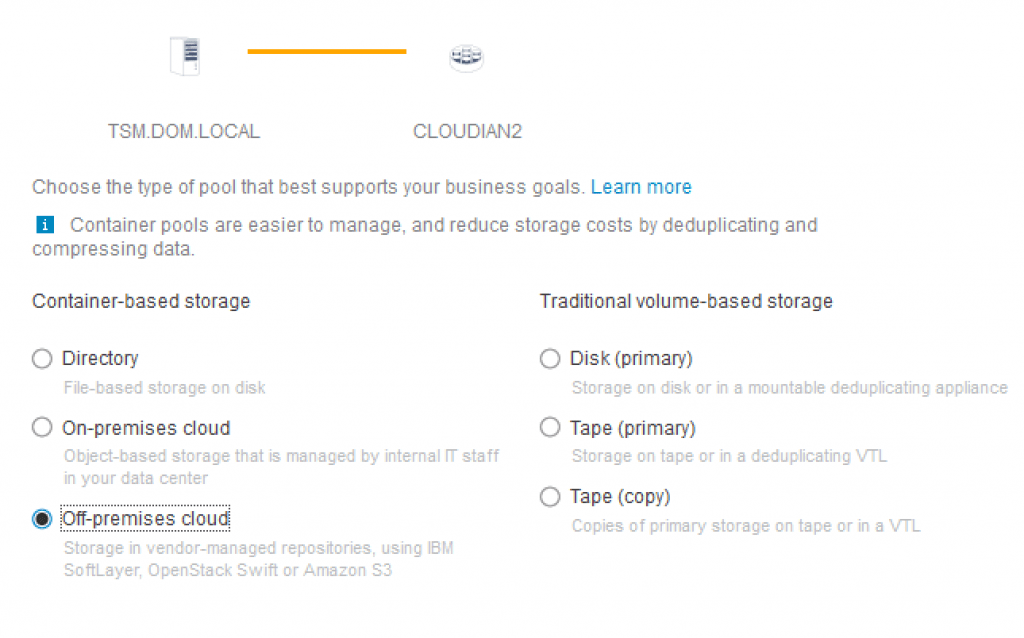
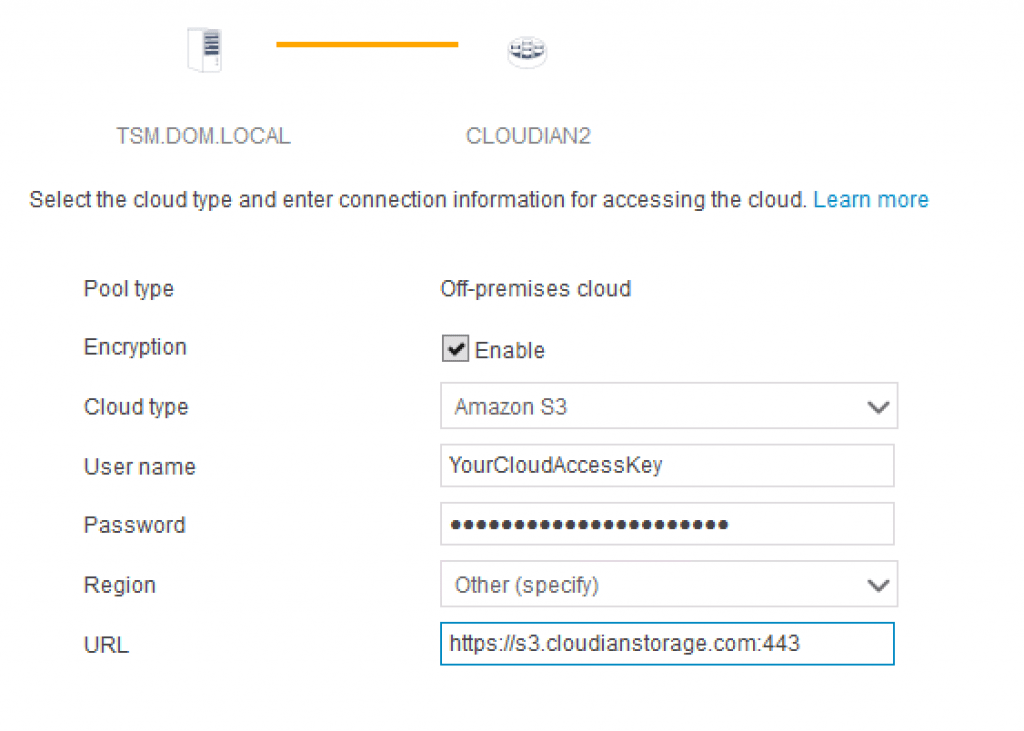
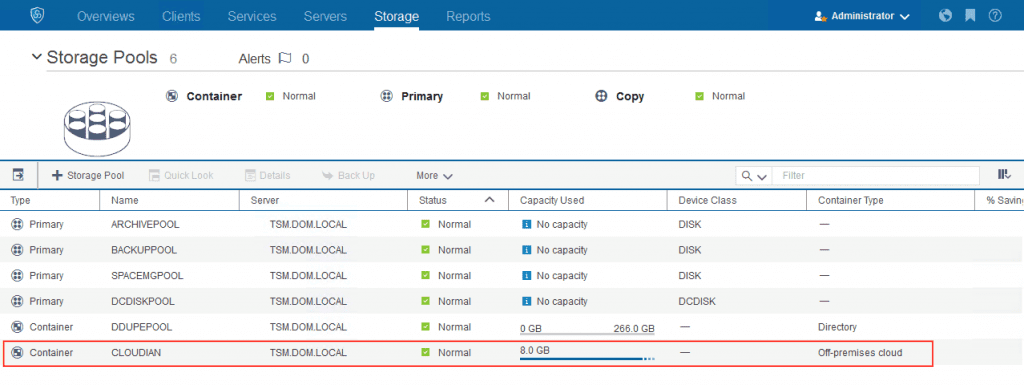
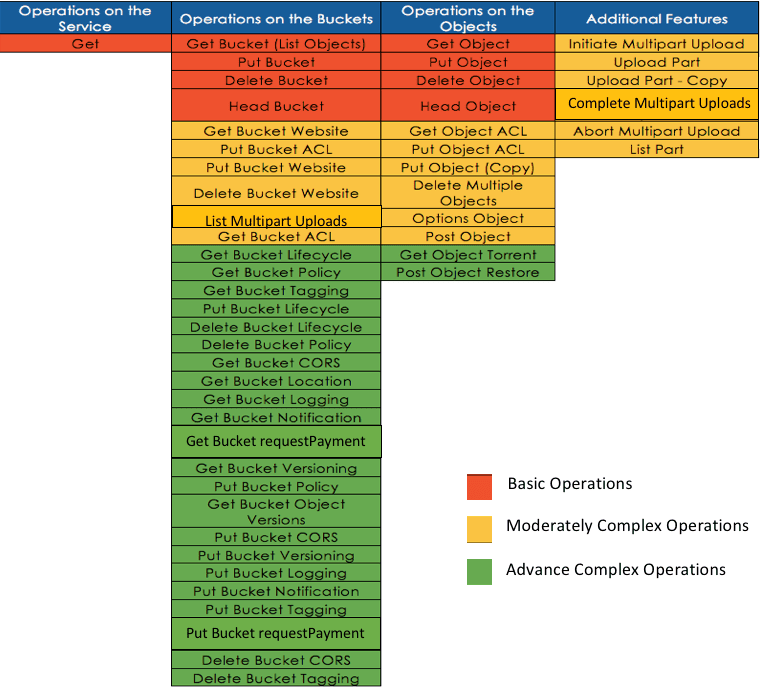
By now you probably know that Cloudian is by far the most compliant Amazon S3 storage. And this S3 compliance is not just about data path commands – it is also about the management experience such as establishing buckets.
What’s more, doubling down on this differentiation, Cloudian and Amazon recently announced a relationship whereby you can bill via Amazon for your on-premise Cloudian storage. In both cases Cloudian is the first solution with this level of integration and partnership.
2) DevOps
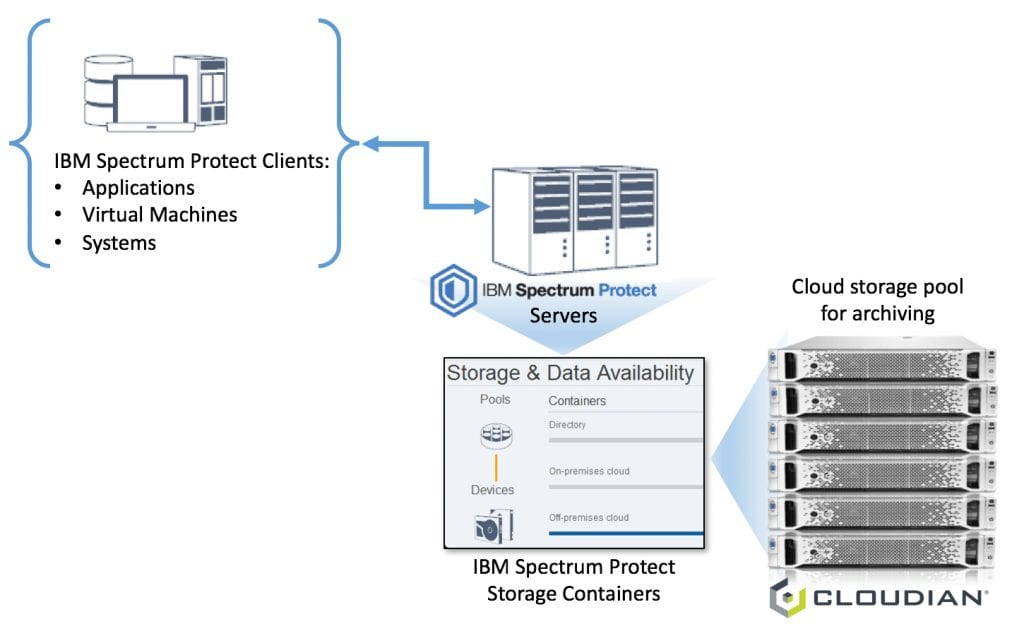
If you’re an enterprise doing DevOps, you should look at Cloudian. That’s because the automation that serves as the foundation for DevOps is greatly simplified by the API consistency that Cloudian delivers.
If your developers are on the front lines of responding to new full stack competitors, you don’t want them hacking together their own storage infrastructure. To deliver on the promise of “just like Amazon S3, on premise and hybrid”, Cloudian has to make distributed system management simple. This is insanely difficult.
In a recent A16Z podcast, Marc Andreessen commented that there are only a few dozen great distributed systems architects and operators in the world today. If you already employ a few of them, and they have time on their hands, then maybe you should just grab Ceph and attempt to roll your own version of what Cloudian delivers. Otherwise, you should be a Cloudian user.
3) Mobility
Architectures have changed with mobility in mind. User experience is now further abstracted from the underlying infrastructure.
In the old scale-up storage world, we worried a lot about IOPS for particular read/write workloads. But when RF is your bottleneck, storage latency is less of a concern. Instead, you need easy to use, massively scalable, geographically disperse systems like object storage, S3, and Cloudian.
4) Open source and a fear of lock-in
Enterprises want to minimize their lock-in to specific service providers. The emergence of a de-facto standard, Amazon S3, now allows providers and ISVs to compete on a level playing field. Google is one example. They now offer S3 APIs on their storage service offerings. If your teams need to learn a new API or even a new set of GUIs to go with a new storage vendor, then you are getting gradually locked in.
5) Machine learning
Machine learning may be the killer-app for big data. In general, there is one practical problem with training machine learning: That is, how do we get the compute to the data rather than the other way around?
The data is big and hard to move. The compute is much more mobile. But even then, you typically require advanced schedulers at the compute layer – which is the focus of entire projects and companies.
The effectiveness of moving the compute to the data is improved if information about the data is widely available as metadata. Employing metadata, however, leads to a new problem: it’s hard to store, serve, and index this metadata to make it useful at scale. It requires an architecture that is built to scale and to serve emerging use cases such as machine learning. Cloudian is literally years ahead of competitors and open source projects in this area.
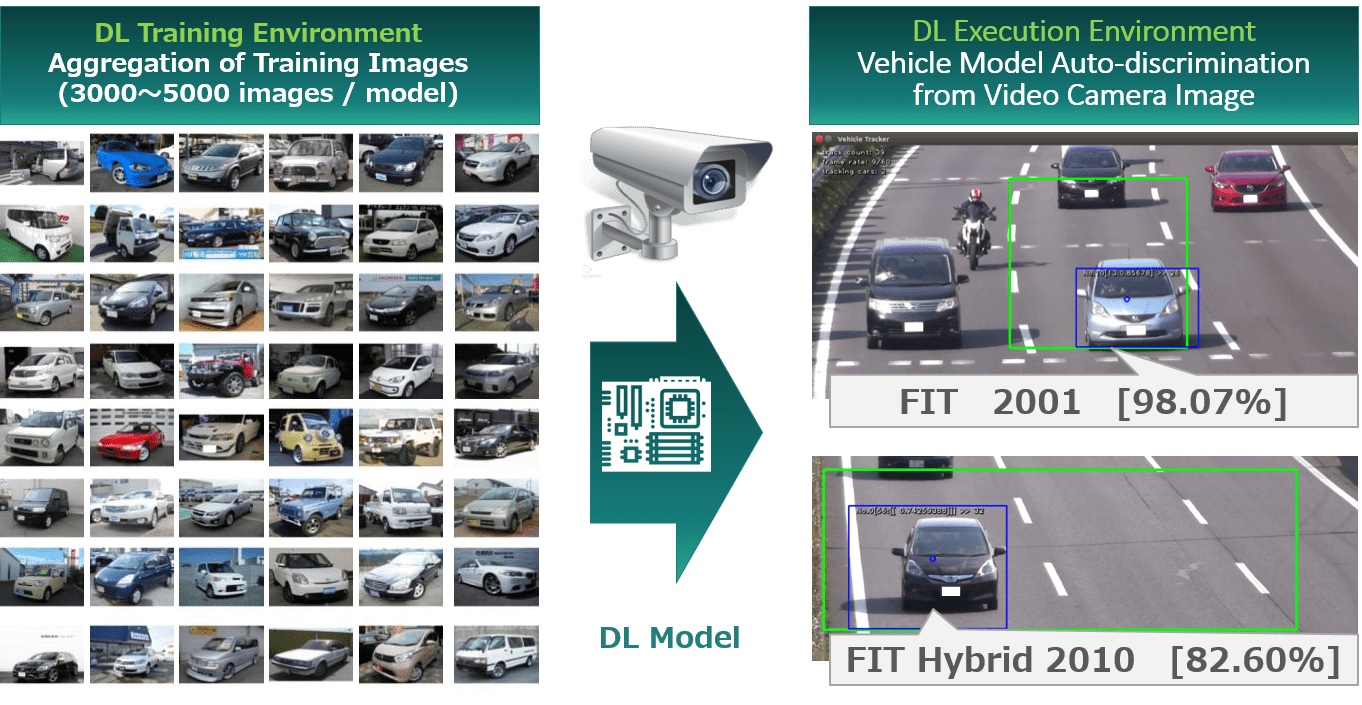
For a real world example, look no further than Cloudian’s work with advertising giant Dentsu to deliver customized ads to Tokyo drivers. Here, Cloudian demonstrates the kind of breakthrough applications that can be delivered, due in part to a rich metadata layer Read more here, and see what is possible today with machine learning and IoT.
There is a lot to consider when investing in technology. You need companies that understand and can exploit relevant trends. But even more so, you need a great team. In Cloudian you’ve got a proven group that emphasizes product quality and customer success over big booths and 5 star parties.
Nonetheless, I thought it worth putting Cloudian’s accelerating growth into the context of five major themes. I hope you found this useful.