In the article below, recently published in The New Stack, I discuss the benefits of cloud-native applications for edge use cases and the challenge that lack of standardization poses to broader adoption.
The Challenge of Bringing Cloud Native Apps to the Edge
With the help of the Cloud Native Computing Foundation, enterprises have made major progress in adopting cloud native technologies in public cloud, private cloud, and hybrid cloud environments. The next step is to bring these technologies to the edge. Just like public cloud, private cloud and hybrid environments, the edge will benefit tremendously from better portability, improved agility, expedited app development cycles and minimized vendor lock-in that cloud native adoption delivers. Before this can happen, however, the industry must first overcome a major challenge — the lack of standardization.
How Cloud Native Apps Benefit Edge Use Cases
App portability and agility are perhaps the biggest advantages of cloud native technology. Using Kubernetes and its resource-aware scheduling and abstraction of the underlying operating system and hardware, a software developer can approach the goal of creating an app once and then running it anywhere.
This flexibility is extremely valuable for all kinds of different edge use cases. Consider a common example: video surveillance. Imagine a security camera monitoring an electrical substation. The camera is continually collecting raw video at this edge endpoint. With massive volumes of streaming data being generated, the IT team naturally needs an app to filter out all the unimportant footage (when no motion is occurring or if there’s insignificant motion, such as a plane flying in the distant sky) and send only the meaningful footage (when significant motion is occurring, such as a person approaching the substation) to a central cloud or hub for human review.
In this case, a single cloud native app can be run at both the edge and the cloud. Furthermore, it can be used for different content transformation purposes in each location. At the edge, the app’s machine learning capabilities perform content filtering and send only important footage to the cloud. In the cloud, humans use the app’s analytics capabilities to perform additional editing and post-processing on that video footage to determine whether suspicious activity is occurring and help identify people when necessary.
With a cloud native app, certain aspects can be run at the edge and other aspects can be run in the cloud. Similarly, the same app can deployed at many different edge endpoints, and in each location, the app can be employed differently. For example, the content transformation app could have unique motion sensitivity settings at every surveillance camera, changing which video footage is filtered from each device.
Standardization
There’s a major hurdle preventing cloud native apps from being widely deployed at the edge today. CNCF projects are all open source — and open source approaches will be challenging to implement at the edge. Why? For open source projects to succeed, they require standardization of both software and hardware.
However, as it stands today, there isn’t much standardization in either edge software or hardware, particularly the latter. Just take a look at how fractured the current hardware market is: e.g., leading home edge devices from Amazon, Apple and Google all employ their own standards and offer little interoperability. For cloud native technology to work at the edge, therefore, the industry must focus their efforts on achieving broad software and hardware standardization.
When it comes to edge deployments, the software players are certainly further along in these efforts than their hardware counterparts. While there’s still much to be done, vendors such as IBM/Red Hat and SUSE/Rancher Labs have led the way in driving early edge software standardization, including work on operating systems and APIs. This isn’t surprising, as the same organizations have also recently been at the front of the pack in promoting on-prem Kubernetes and cloud native adoption.
API standardization is an especially important piece of the puzzle for software. High-quality, standardized APIs are key to supporting certain functionalities in any computing environment. For instance, the Amazon Web Services‘ S3 API, standardized by Amazon, provides limitless scalability for object storage deployments (and it works well on-prem, in the public cloud, and at the edge).
There are existing storage and networking APIs, currently used in highly distributed computing environments, that can effectively be extended to the edge. As mentioned above, the S3 API is one. Still, the industry must standardize many more APIs to support very specialized functions that are unique to the edge.
Streaming APIs are among the most critical. An autonomous vehicle’s steering software has to make life-or-death decisions in real-time. While there are existing streaming APIs that can be applied for edge use cases like video surveillance, more robust streaming APIs must be developed and standardized to support next-generation applications such as those for self-driving cars. In addition to streaming APIs, edge apps also need standardized APIs to enable important operations like data windowing and mapping, as well as better control plane APIs.
Efforts to standardize edge hardware are only in their infancy. Chipmakers such as Intel and Nvidia will play the biggest role here. Edge devices need to be low-power and cost-effective. It’s the chip technology, which provides the computing and storage capabilities, that determines how energy- and cost-efficient these devices can be. Intel and Nvidia’s design decisions will ultimately influence how device manufacturers build edge products. Eventually, these types of manufacturers will need to work together to help standardize certain components.
Conclusion
These standardization challenges will eventually be solved. Organizations have realized edge computing’s tremendous value. And they’re recognizing that to fulfill its potential, the edge is where innovative new technology, such as cloud native tech, needs to be developed and deployed. In addition, over the past 15-20 years, leading software and hardware vendors have made major progress supporting highly distributed systems and have found a way to make loosely coupled devices work well together. The industry will leverage this expertise, along with a rapidly maturing Kubernetes ecosystem, to bring cloud native apps to the edge.
 Gary Ogasawara, CTO, Cloudian
Gary Ogasawara, CTO, Cloudian
 Jon Toor, CMO, Cloudian
Jon Toor, CMO, Cloudian AWS Outposts gives you cloud-like services in your data center. Now Cloudian provides AWS-validated S3-compatible storage on-prem to help you do more with Outposts. With Cloudian, you can expand your Outposts use cases to applications where data locality and latency are key.
AWS Outposts gives you cloud-like services in your data center. Now Cloudian provides AWS-validated S3-compatible storage on-prem to help you do more with Outposts. With Cloudian, you can expand your Outposts use cases to applications where data locality and latency are key.
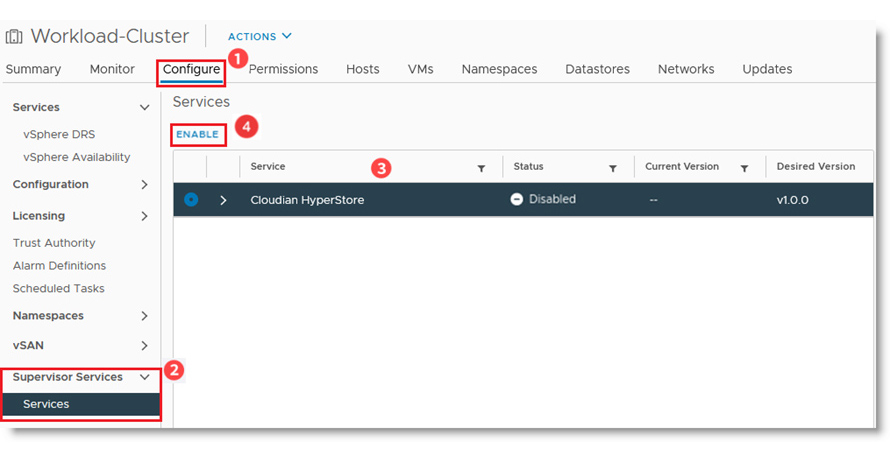
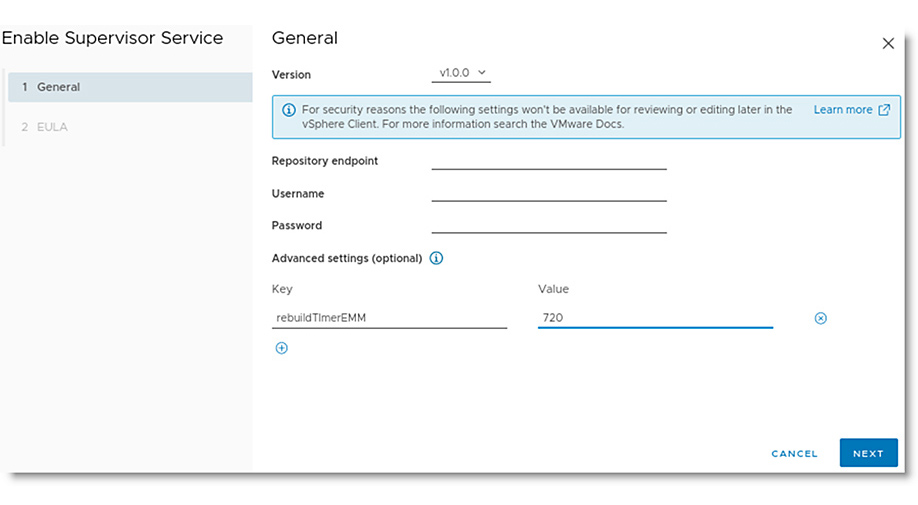

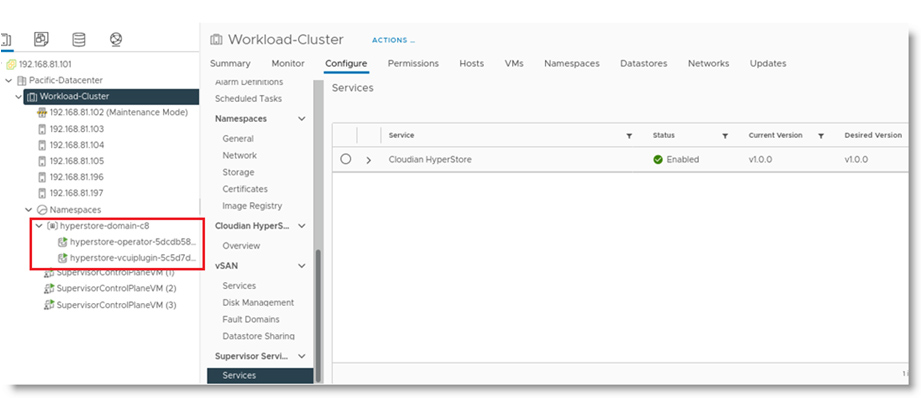
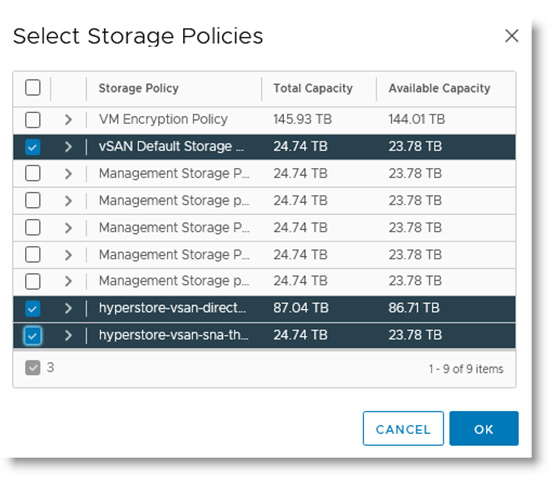
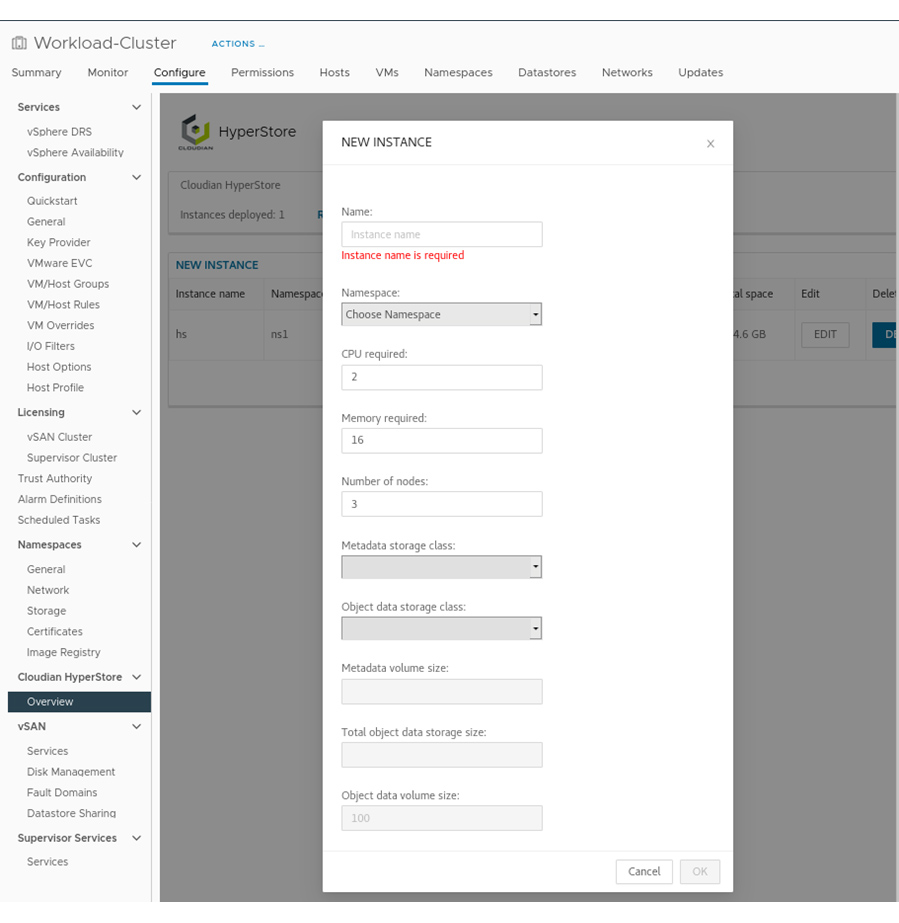

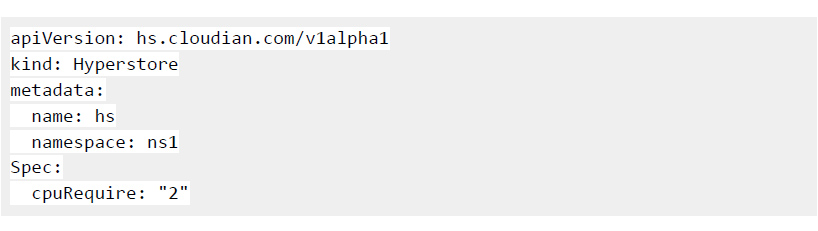
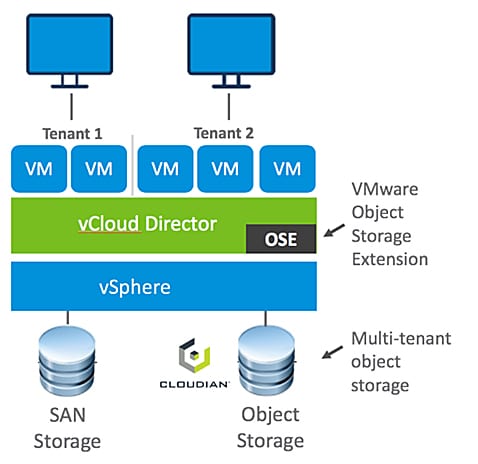
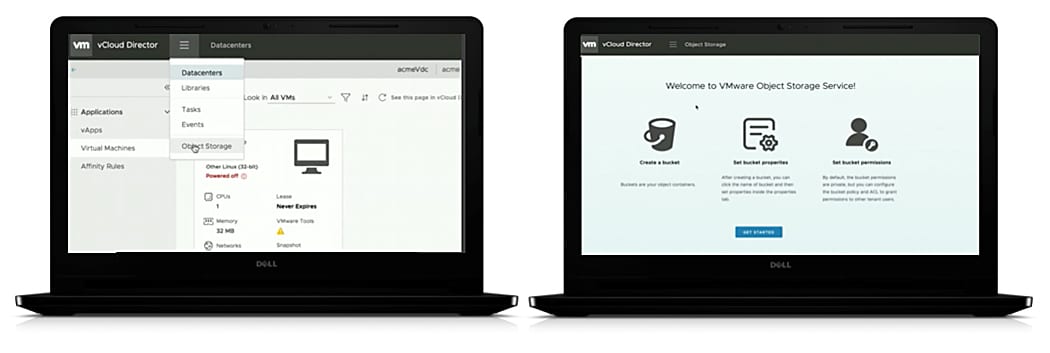
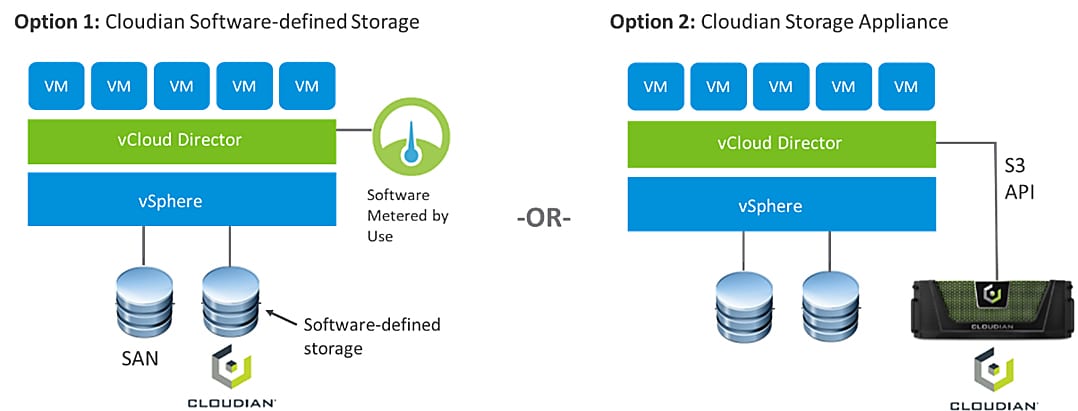
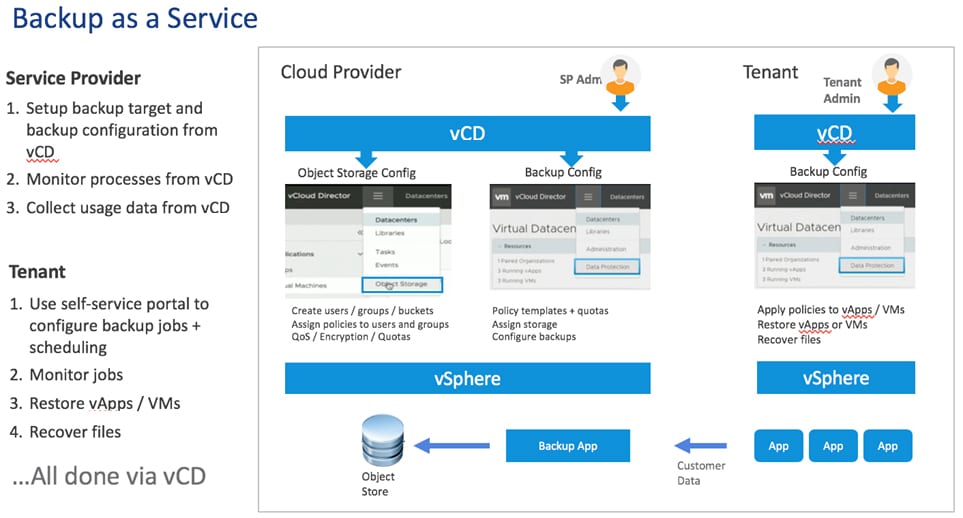
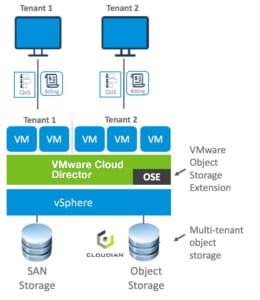 The solution combines the power of:
The solution combines the power of: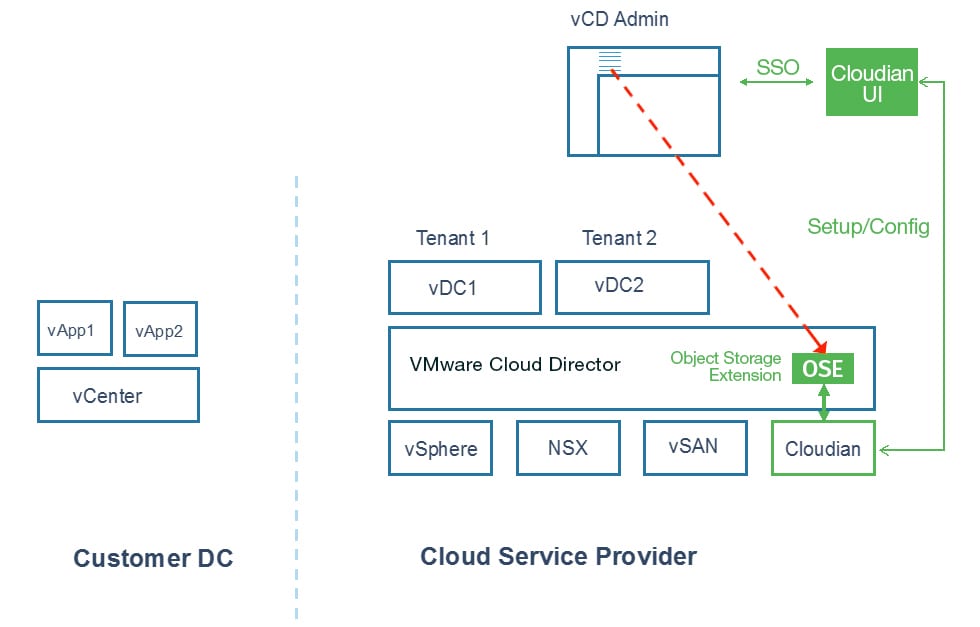 VMware Cloud Director creates virtual data centers with elastic pools of cloud resources that are seamless to provision and easy to consume. It creates a fluid hybrid cloud fabric between an on-premise infrastructure and Cloud Service Provider, offering a best-in-class private/hybrid cloud with on-demand elasticity, streamlined on-ramp, native security, and hybridity.
VMware Cloud Director creates virtual data centers with elastic pools of cloud resources that are seamless to provision and easy to consume. It creates a fluid hybrid cloud fabric between an on-premise infrastructure and Cloud Service Provider, offering a best-in-class private/hybrid cloud with on-demand elasticity, streamlined on-ramp, native security, and hybridity.