IBM Spectrum Protect (formerly IBM Tivoli Storage Manager) solution provides the following benefits:
- Supports software-defined storage environments
- Supports cloud data protection
- Easily integrates with VMware and Hyper-V
- Enables data protection by minimizing data loss with frequent snapshots, replication, and DR management
- Reduce the cost of data protection with built-in efficiencies such as source-side and target-side deduplication
IBM Spectrum Protect has also enhanced its offerings by providing support for Amazon S3 cloud storage (version 7.1.6 and later) and IBM Spectrum Protect version 7.1.6 was just released on June 17th, 2016. I was actually a little nervous and excited at the same time. Why? Because Cloudian HyperStore has a S3 guarantee. What better way to validate that guarantee than by trying a plug-and-play with a solution that has just implemented support for Amazon S3?
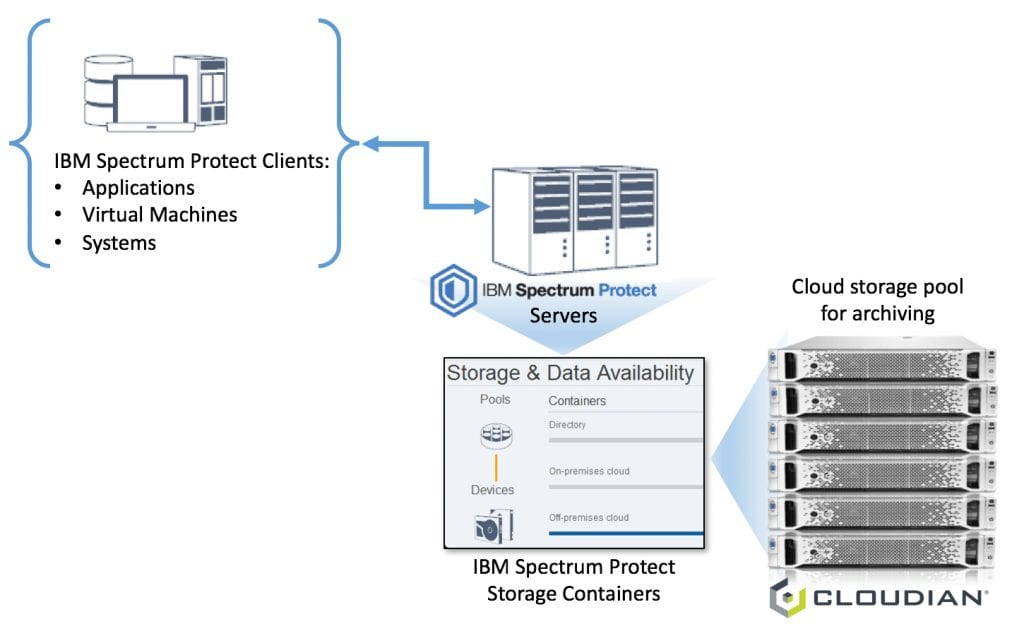
And the verdict? Cloudian HyperStore configured as “Cloud type: Amazon S3” works right off the bat with IBM Spectrum Protect. You can choose to add a cloud storage pool from the V7.1.6 Operations Center UI or use the Command Builder. The choice is yours.
We’ll look at both the V7.1.6 Operations Center UI and the Command Builder to add our off-premise cloud storage.
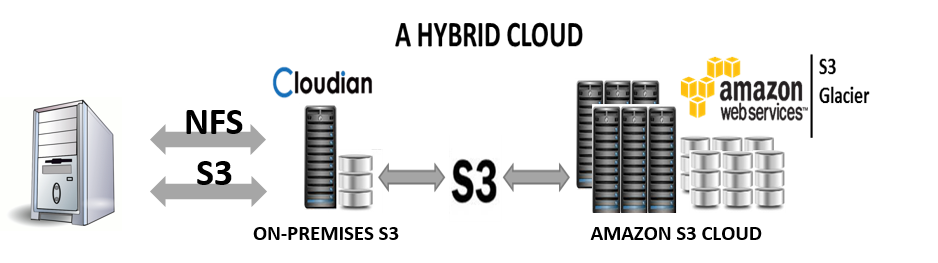
NOTE: Cloudian HyperStore can be deployed as your on-premise S3 cloud storage but it has to be identified as an Amazon S3 off-premise cloud storage and you have to use a signed SSL certificate.
Here’s how you can add an Amazon S3 cloud storage or a Cloudian HyperStore S3 cloud storage into your IBM Spectrum Protect storage pool:
From the V7.1.6 Operations Center UI
From the V7.1.6 Operations Center console, select “+Storage Pool”.

In the “Add Storage Pool:Identity” pop-up window, provide the name of your cloud storage and the description. In the next step of the “Add Storage Pool:Type”, select “Container-based storage:Off-premises cloud”.
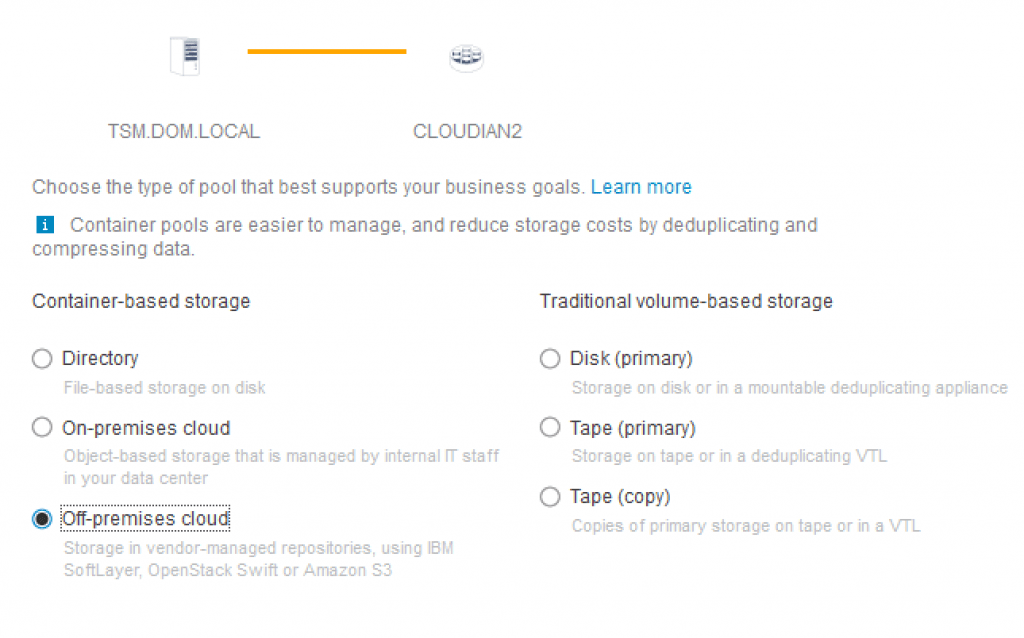
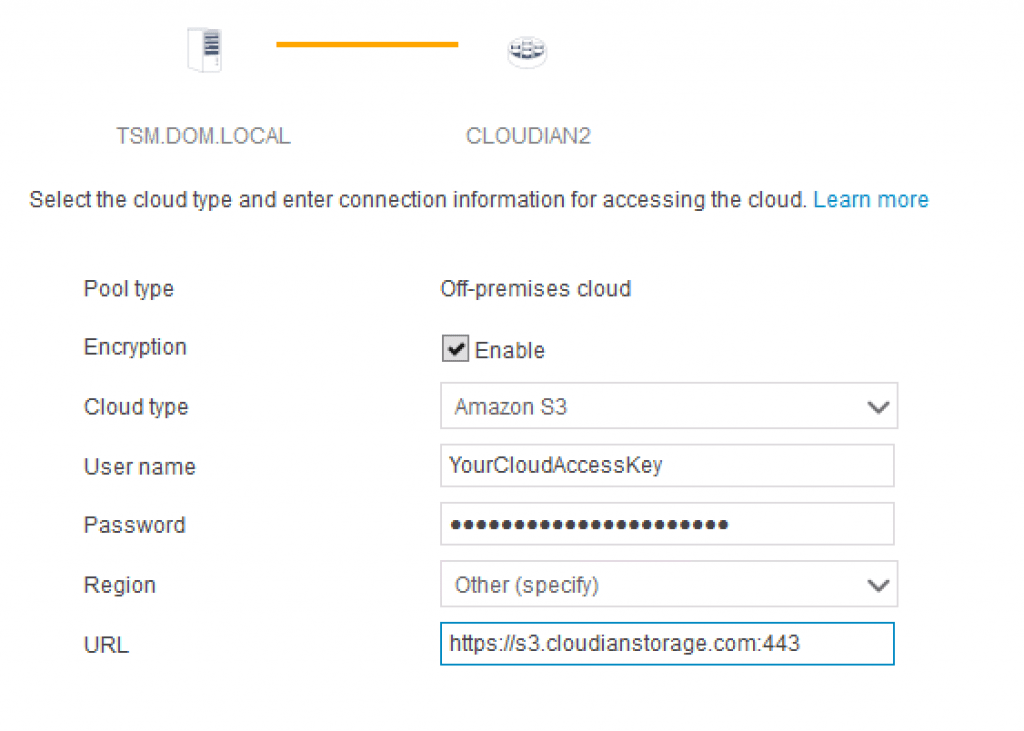
Click on “Next” to continue. The next step in the “Add Storage Pool:Credentials” page is where it gets exciting. This is where we provide the information for:
- Cloud type: Amazon S3 (Amazon S3 cloud type is also used to identify a Cloudian HyperStore S3)
- User Name: YourS3AccessKey
- Password: YourS3SecretKey
- Region: Specify your Amazon S3 region (for Cloudian HyperStore S3, select “Other”)
- URL: If you had selected an Amazon S3 region, this will dynamically update to the Amazon region’s URL. If you are using a Cloudian HyperStore S3 cloud storage, input the S3 Endpoint Access (HTTPS).
Complete the process by clicking on “Add Storage Pool”.
NOTE: Be aware that there is currently no validation performed to verify your entries when you click on “Add Storage Pool”. Your S3 cloud storage pool will be created. I believe the IBM Spectrum Protect group is addressing this with a validation process for the creation of a S3 cloud storage pool. I hope the step-by-step process that I have provided will help minimize errors with your Amazon S3 cloud storage pool setup.
From the V7.1.6 Operations Center Command Builder
From the V7.1.6 Operations Center Command Builder, you can use the following define stgpool command and you are done adding your off-premise S3 cloud storage pool:
- define stgpool YourCloudName stgtype=cloud pooltype=primary cloudtype=s3 cloudurl=https://s3.cloudianstorage.com:443 access=readwrite encrypt=yes identity=YourS3AccessKey password=YourS3SecretKey description=”Cloudian”
NOTE: You can review the server instance dsmffdc log if there’s errors. It is located in the server instance directory. There’s also a probability that the signed SSL certificate might not be correct.
For example:
06-20-2016 11:58:26.150][ FFDC_GENERAL_SERVER_ERROR ]: (sdcloud.c:3145) com.tivoli.dsm.cloud.api.ProviderS3 handleException com.amazonaws.AmazonClientException Unable to execute HTTP request: com.ibm.jsse2.util.h: PKIX path building failed: java.security.cert.CertPathBuilderException: unable to find valid certification path to requested target
[06-20-2016 11:58:26.150][ FFDC_GENERAL_SERVER_ERROR ]: (sdcntr.c:8166) Error 2903 creating container ibmsp.a79378e1333211e6984b000c2967bf98/1-a79378e1333211e6984b000c2967bf98
[06-20-2016 11:58:26.150][ FFDC_GENERAL_SERVER_ERROR ]: (sdio.c:1956) Did not get cloud container. rc = 2903
Importing A Signed SSL Certificate
You can use the IBM Spectrum Protect keytool –import command to import the signed SSL certificate. However, before you perform the keytool import process, make a copy of the original Java cacerts.
The Java cacerts is located in IBM_Spectrum_Protect_Install_Path > TSM > jre > security directory.
You can run the command from IBM_Spectrum_Protect_Install_Path > TSM > jre > bin directory.
For example, on Windows:
-
- ./keytool –import ../lib/security/cacerts –alias Cloudian –file c:/locationofmysignedsslcert/admin.crt
Enter the keystore password when prompted. If you haven’t updated your keystore password, the default is changeit and you should change it for production environments. When you are prompted to “Trust this certificate?”, input “yes”.
NOTE: Keep track of the “Valid from: xxxxxx” of your signed SSL certificate, you will have to import a new certificate when the current one expires.
By the way, if you encounter error “ANR3704E sdcloud.c(1636): Unable to load the jvm for the cloud storage pool on Windows 2012R2”, update the PATH environment variable on the Spectrum Protect Server:
IBM_Spectrum_Install_Path\Tivoli\TSM\jre\bin\j9vm and also set the JVM_LIB to jvm.dll.
Here’s what your Amazon S3 cloud storage type looks like from IBM Spectrum Protect V7.1.6 Operations Center console:
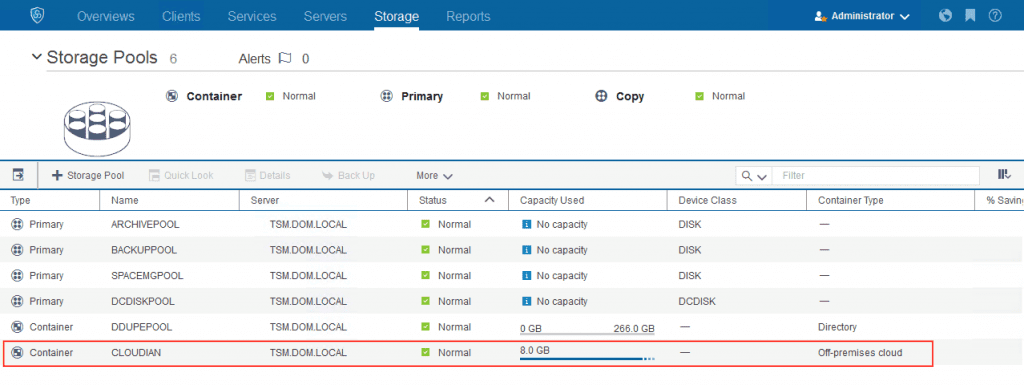
And you’re off! If you encounter any issues during this process, feel free to reach out to our support team.
You can also learn more by downloading our solution brief.











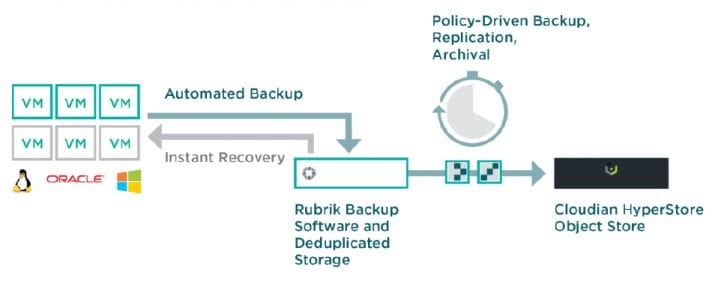
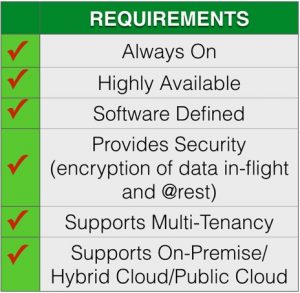 But in order to serve and protect your data for the always on, always available IoT world, what requirements should we take into account before deploying any data protection or storage solution? If you are a data protection geek, you’ll most likely see some of your requirements being listed on the right. If you are a data protection solutions provider, you guys definitely rock! Data protection solutions such as Commvault, NetBackup, Rubrik, Veeam, etc. are likely the solutions you have in-house to protect your corporate data centers and your mobile devices. These are software-defined and they are designed to be highly available for on-premise or in-the-cloud data protection.
But in order to serve and protect your data for the always on, always available IoT world, what requirements should we take into account before deploying any data protection or storage solution? If you are a data protection geek, you’ll most likely see some of your requirements being listed on the right. If you are a data protection solutions provider, you guys definitely rock! Data protection solutions such as Commvault, NetBackup, Rubrik, Veeam, etc. are likely the solutions you have in-house to protect your corporate data centers and your mobile devices. These are software-defined and they are designed to be highly available for on-premise or in-the-cloud data protection.