

S3 Compatible Storage, On-Prem
Today’s emerging on-prem enterprise storage medium is S3 compatible storage. Initially used only in the cloud, S3 storage is now being extended to on-prem and private cloud deployments.
The term “S3 compatible” means that the storage employs the S3 API as its “language.” Applications that speak the S3 API should be able to plug and play with S3 compatible storage.
A growing number of applications now support this storage type, thus benefitting from its unique attributes:
- Scale: Designed to grow limitlessly within a single namespace
- Geo-distribution: A single storage system can span multiple sites
- Cost: Purpose-built to run on industry-standard servers, thus benefitting from the volume and efficiencies of that industry
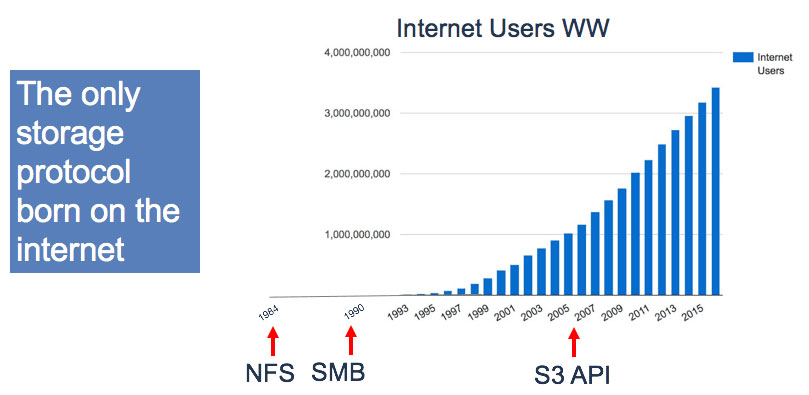
- Reliable data transport: The only storage type invented in the age of the Internet, S3-compatible storage is built to manage and move massive data volumes over WANs
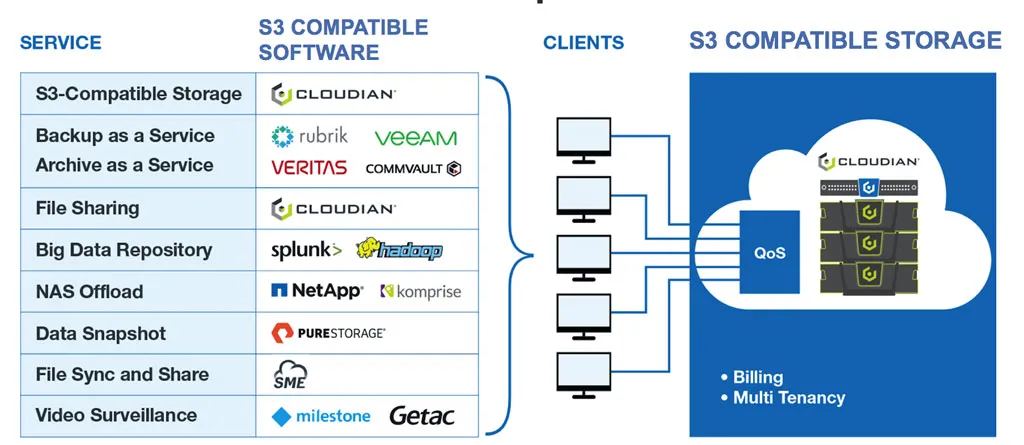
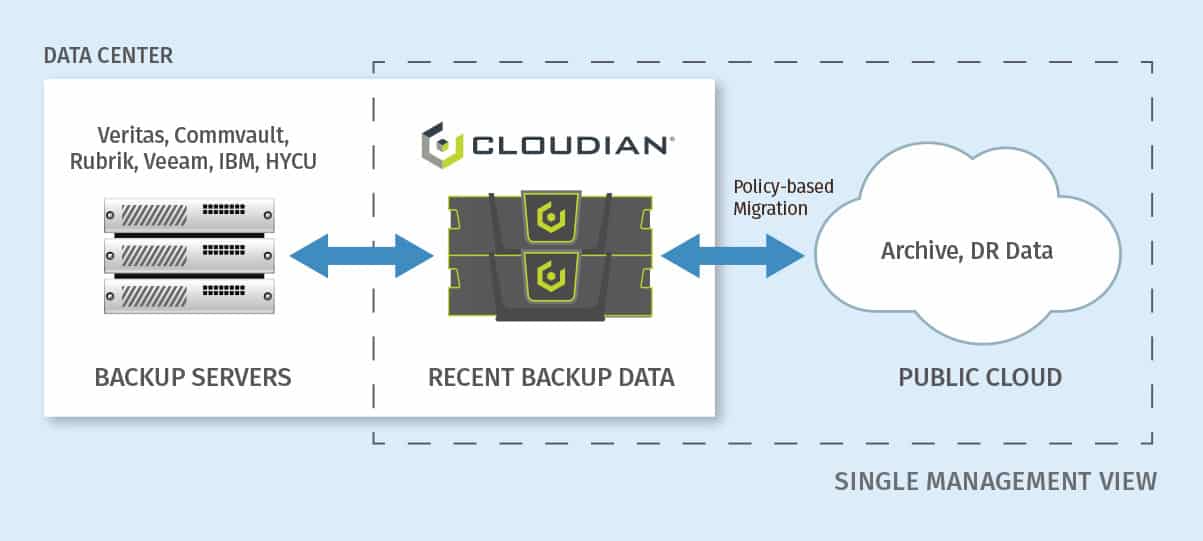
Cloudian specializes in S3-compatible storage, but other examples of applications and devices the now employ S3 are Rubrik, Veeam, Commvault, Splunk, Pure Storage, Adobe, VERITAS, Hadoop, NetApp, EMC, Komprise, and more.
This is part of an extensive series of articles about S3 Storage.
Clarifying the Terms
But what is S3-compatible storage? This storage type goes by multiple names and can also be called:
Object storage: The underlying technology for S3 compatible storage is object storage. Over the years, multiple APIs have been used to access object storage, but the S3 API is now the most common.
Cloud storage: Most large-scale cloud storage today is object storage, and most of it employs the S3 API. There are multiple ways of referring to essentially the same thing: S3-compatible storage.
Benefits of S3 Compatible Storage On-Prem
There are 5 key reasons to deploy S3 compatible storage in your data center:
- Scale: S3-compatible solutions are designed to scale in a single namespace, and without disruption, to an exabyte. Grow your storage without adding workload.
- 70% less cost than public cloud: With industry-standard hardware, these solutions deliver the greatest value: less cost per GB and higher density. Also, no ingress/egress fees.
- Performance: Hardware is in your data center for low latency and high bandwidth.
- Control: Data is behind your firewall, so you consistently apply security and control access.
- Cloud compatibility: S3 is compatible with cloud storage, so you can employ cloud when you need it, without disruption. Capitalize on the growing ecosystem of S3 compatible applications. Seamlessly move data and applications from on-prem to cloud.
The S3 API
S3 compatible storage is built on the Amazon S3 Application Programming Interface, better known as the S3 API, the most common way in which data is stored, managed, and retrieved by object stores. Originally created for the Amazon S3 Simple Storage Service (read about the API here), the widely adopted S3 API is now the de facto standard for object storage, employed by vendors and cloud providers industry-wide.
Not All S3 Compatible Storage APIs Are Equal
Compared with established file protocols such as NFS, the S3 API is relatively new and rapidly evolving. Among object storage vendors, S3 API compliance varies from below 50% to over 90%. This difference becomes material when an application — or an updated version of that app— fails due to S3 API incompatibility.
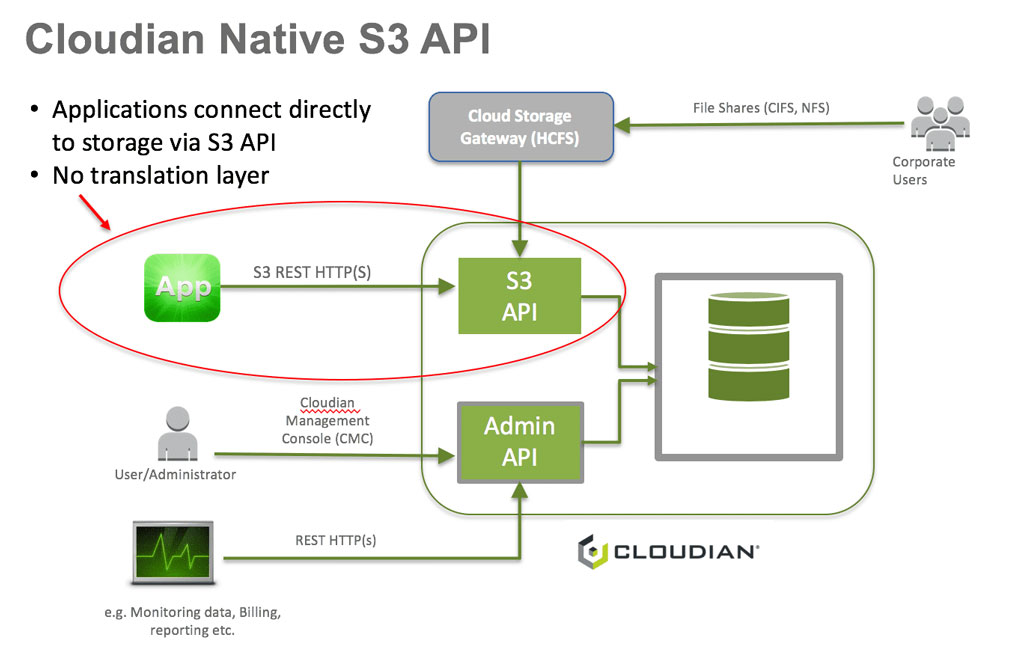
Cloudian is the only object storage solution to exclusively support the S3 API. Launched in 2011, Cloudian’s many years of S3 API development translate to the industry’s highest level of compliance.
Employing the S3 API makes an object storage solution flexible and powerful for three reasons:
1) Standardization in S3 Compatible Storage
With Cloudian, any object written using the S3 API can be used by other S3-enabled applications and object storage solutions; the existing code works out of the box.
2) Maturity
The S3 API provides a wide variety of features that meet virtually every need for an object store. End users planning to deploy object stores can access the plentiful resources of the S3 community — both individuals and companies.
3) Rich Feature Set
The S3 API is the only storage “language” created in the era of the internet. The other common storage protocols (SMB and NFS) were created prior to the internet’s meteoric growth, and therefore did not factor in the needs of this infrastructure. As a result, only the S3 API includes features such as multi-part upload that make it easy to reliably transfer large files over dodgy WAN links.
The Cloudian Difference
Among the S3 compatible storage vendors, only Cloudian HyperStore was built from the start on the S3 API.
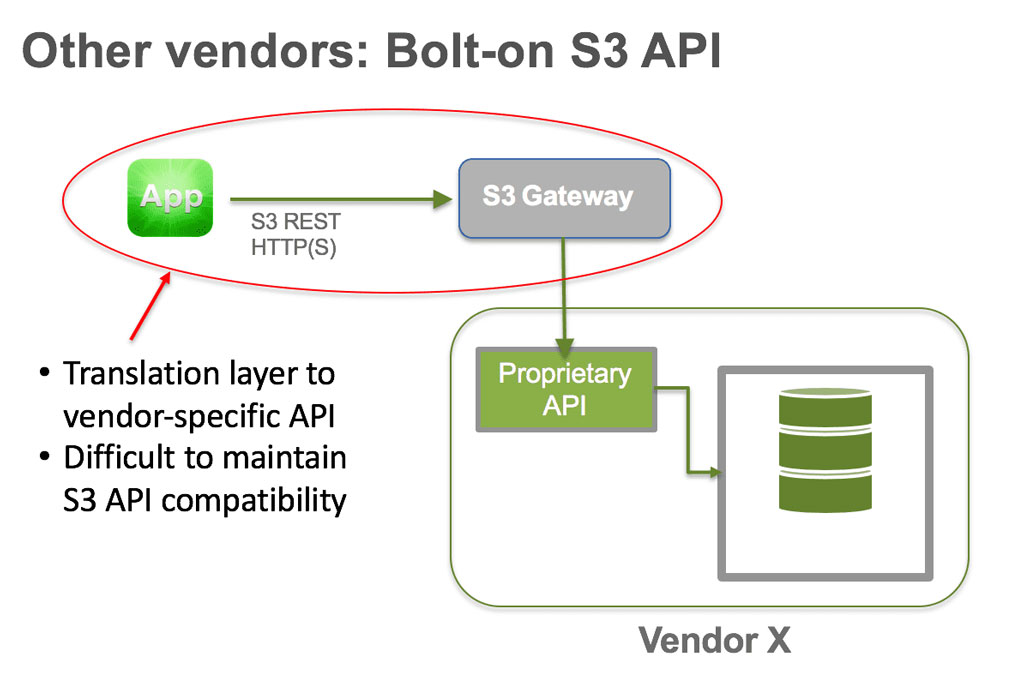
Translation Layers Introduce Potential Compatibility Challenges
Competitive solutions employ a translation layer (or some sort of “access layer” or software gateway), which introduces the risk of compatibility challenges. Cloudian has no translation layer, hence we refer to it as “S3 Native.”
Cloud Storage in the Data Center
The combination of object storage and the de facto language standard now creates the option for cloud-connected storage in the data center. For the cloud, AWS has set the standard with the S3 Storage Service. Now data center managers can capitalize on that identical set of capabilities in their own data center with Cloudian S3 compatible storage.
Examples of S3-Compatible Storage
The S3 API is now widely supported among on-prem storage platforms. In addition to Cloudian, the API is supported by NetApp, Dell/EMC, Pure Storage, Minio, VAST Data, Scality, and others.
What makes Cloudian the best on-prem solution for S3-compatible storage?
- Highest S3 API compatibility: Fully-native implementation and a laser focus on the S3 API since 2012.
- Proven scalability: Proven at large-enterprise, government and service provider deployments. Start small and scale to hundreds of nodes.
- AI-ready performance: 35MB/sec read throughput per node with NVIDA GPUDirect support keeps GPUs fully utilized.
See the S3 API at Work
The City of Montebello uses the S3 API as a mechanism for streaming live video from busses to a central monitoring facility where it is recorded and stored with metadata to assist with search.



{kind=link}